Der Split-Apply-Combine Approach
Der sogenannte Split-Apply-Combine Approach in eine sehr mächtige Codingstrategie. Er wendet in summarize() oder mutate() gewrappte Funktionen getrennt auf Untergruppen des Datensatzes an und führt die Ergebnisse anschließend wieder zusammen:
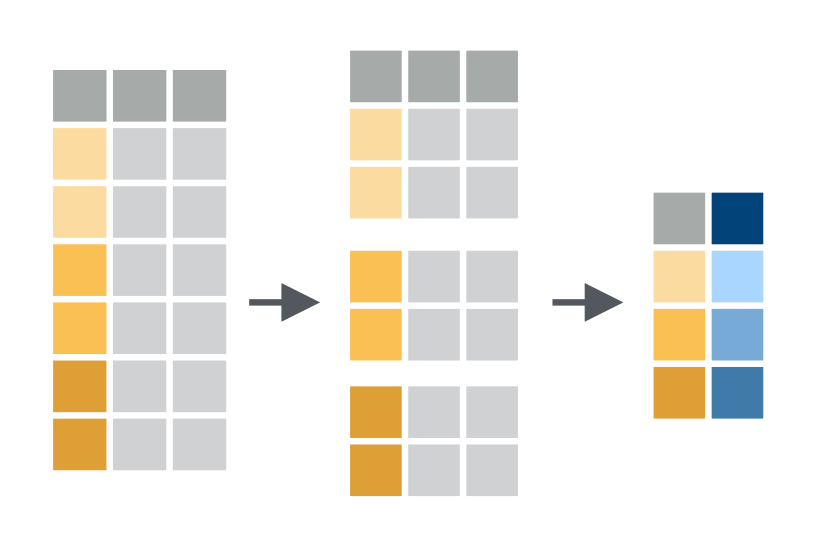
MW und SD der bill-Variablen je Species
TipBeispielstudie
Angenommen ein Forscher:innenteam möchte Mittelwert und Standardabweichungen der bill-Variablen je Spezies berichten - was wäre eine geeignete Syntax?
- 1
-
Nimm das Objekt/den Datensatz
penguinsund - 2
-
Splitte ihn Unterdatensätz je nach Ausprägung von
species - 3
- Berechne Zusammenfassungen von Variablen
Übung 1
Führen Sie die den obigen Code aus. Diskutieren Sie die Größe der Mittelwertsunterschiede als »bedeutsam« bezeichnen würden.
TipEine Lösung
bill_length unterscheidet sich bspw. zwischen Adelie und Chinstrap um ca. 10mm. Nimmt man an, dass die bill_length normalverteilt ist, entspricht das bei einer \(\overline{SD} \approx 3\) einem Cohen’s \(d \approx 3.3\), also liegen 99.9% der Bills der Gentoo länger als der durchschnittliche Adelie Bill bzw. die beiden Gruppen überlappen nur zu 9,9% (interaktive Übersicht).
rowwise als Extremfall
Man kann mit der Funktion rowwise() den Datensatz in so viele Teildatensätze aufteilen wie er Zeilen hat. Das ist für Sozialwissenschaftler:innen sehr nützlich, um z.B. Skalenwerte zu bilden. Möchte man etwa den Mittelwert von z-standandardisierten bill-Variablen berechnen, kann man in mutate() nicht mean() verwenden, da dies ja eine summary-Funktion ist und den Mittelwert der ganzen Spalte berechnen würde. Daher verwendet man besser rowwise() im Zusammenhang mit c_across():
penguins %>%
mutate(bill_length_z = (bill_length_mm - mean(bill_length_mm, na.rm = T))/
sd(bill_length_mm, na.rm = T),
bill_depth_z = (bill_depth_mm - mean(bill_depth_mm, na.rm = T))/
sd(bill_depth_mm, na.rm = T)) %>%
rowwise() %>%
mutate(bills_z_mean = mean(c_across(c(bill_length_z, bill_depth_z)))) %>%
select(contains("bill"))# A tibble: 344 × 5
# Rowwise:
bill_length_mm bill_depth_mm bill_length_z bill_depth_z bills_z_mean
<dbl> <dbl> <dbl> <dbl> <dbl>
1 39.1 18.7 -0.883 0.784 -0.0495
2 39.5 17.4 -0.810 0.126 -0.342
3 40.3 18 -0.663 0.430 -0.117
4 NA NA NA NA NA
5 36.7 19.3 -1.32 1.09 -0.117
6 39.3 20.6 -0.847 1.75 0.450
7 38.9 17.8 -0.920 0.329 -0.296
8 39.2 19.6 -0.865 1.24 0.188
9 34.1 18.1 -1.80 0.480 -0.659
10 42 20.2 -0.352 1.54 0.596
# ℹ 334 more rowsCheat Sheet
Auch die Funktionalitäten des Split-Apply-Combine Approaches sind gut im Cheat Sheet abgebildet.