| Kategorie | Vorteile | Nachteile |
|---|---|---|
| Sehr einfache Syntax, wenig Code nötig | Weniger flexibel, begrenzte Anpassungsmöglichkeiten | |
| Automatische gute Designs | Nicht ideal für komplexe oder Publikationsplots | |
| Perfekt für schnelle Explorationsplots | Kaum Unterstützung für Interaktivität | |
| Extrem flexibel und anpassbar | Steilere Lernkurve, mehr Code nötig | |
| Sehr gut für komplexe Visualisierungen | Standarddesign oft zu schlicht | |
| Interaktivität leicht hinzufügbar | Erfordert manuelle Stilisierung für ansprechende Plots |
Das {tidyplots}-Paket
…make both calculations and graphs. Both sorts of output should be studied; each will contribute to understanding.
F. J. Anscombe (1973)
Datenvisualisierung
Datenvisualisierung stellt auch für Sozialwissenschaftler:innen eine essentielle Methode der Datenanalyse dar. Das menschliche System visueller Perzeption ist derart mächtig (Franconeri, Padilla, Shah, Zacks, & Hullman, 2021), dass es bei geeigneten Aufbereitungen selbst Laien leicht möglich ist, komplexere statistische Entitäten wie Effektstärken für Mittelwerte (Schneider, Schmidt, Bohrer, & Merk, 2025) vergleichweise unverzerrt zu rezipieren. Zudem sind graphische Darstellungen sehr gut für die Aufdeckung von Artefakten in Daten und für die explorative Analyse geeignet (Grolemund, 2025).
Unterschiede zwischen {tidyplots} und {ggplot2}
Im Folgenden wird in Visualisierungen mit den Paketen {tidyplots} und {ggplot2} eingeführt. Vergleichende Vor- und Nachteile sind in Tabelle 1 gegeben. Am Ende dieses Abschnitts ist zudem ein Cheatsheet für einen Überblick verlinkt.
{tidyplots}
Die grundlegende Konstruktion erfolgt in {tidyplots} in den folgenden Schritten:
- Festlegung des Datensatzes
- Zuweisung von Variablen des Datensatzes zu
- x-Achse
- y-Achse
- Farbe
- Hinzufügen von grafischen Elementen (Punkte, Balken, …)
- Aufteilung in Unterplots
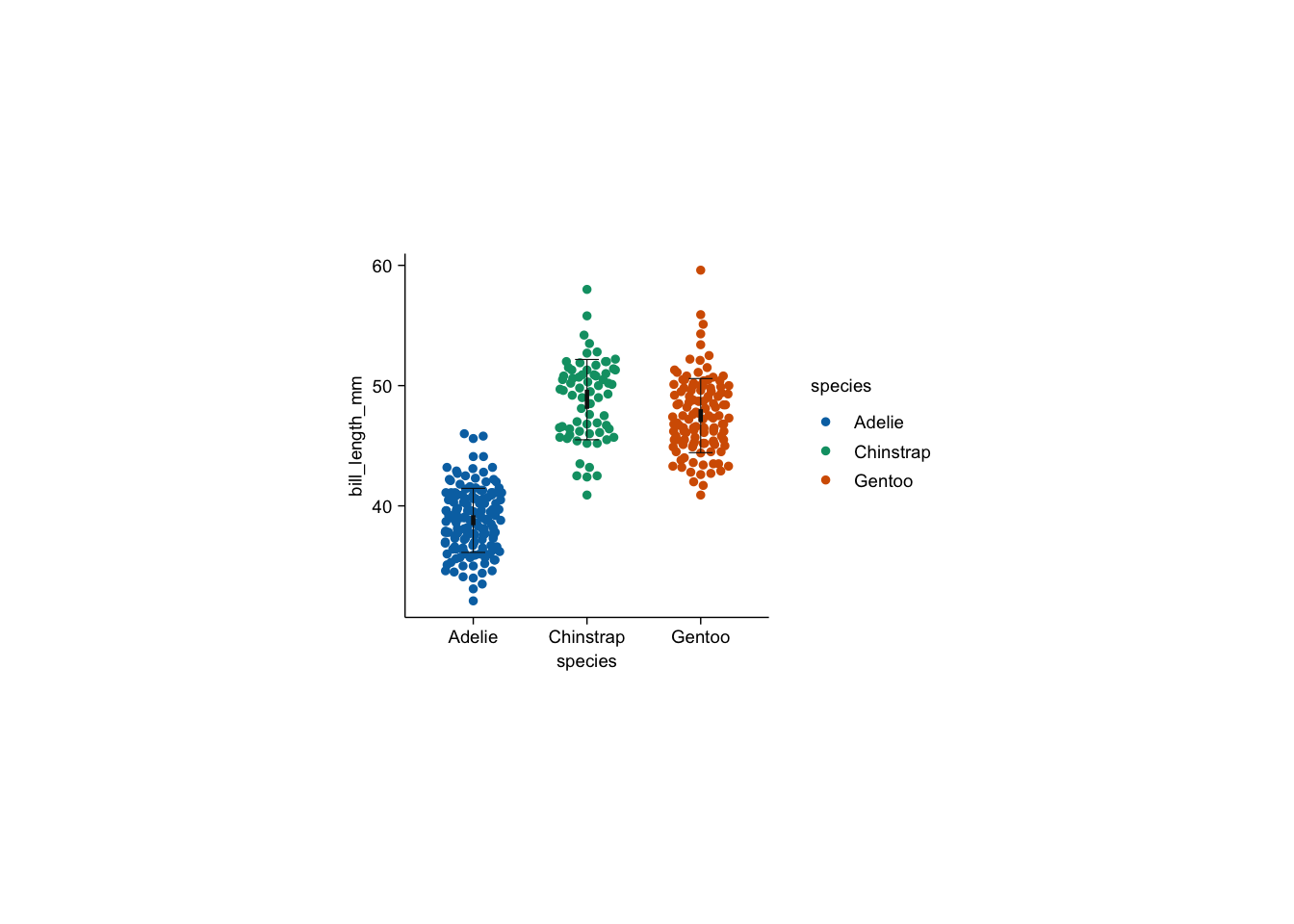
Beispiel 1: bill_length_mm per Species
TippBeispielstudie
Angenommen ein Forscher:innenteam möchte explorieren wie groß die Effekte der Mittelwertunterschiede in bill_length_mm sind und ob diese statistisch signifikant sind. Was wäre ein geeigneter Plot?
- 1
-
Wähle den Datensatz
penguins - 2
-
Lege die Variable
speciesauf die x-Achse - 3
-
Lege die Variable
bill_length_mmauf die y-Achse - 4
-
Enkodiere die Variable
speciesfarblich - 5
- Stelle jeden Datenpunkt sortiert nach dem beeswarm-Algorithmus dar
- 6
- Trage die Standardabweichung als vertikalen Balken der Breite .2,
- 7
- mit horizontalen Enden der Länge .21
- 8
- und der Farbe schwarz auf.
- 9
- Trage ein 95%-Konfidenzinterval als vertikalen Balken der Breite .8,
- 10
- mit horizontalen Enden der Länge 0
- 11
- und der Farbe schwarz auf.
Übung 1: Korrelation bill_depth_mm und bill_length_mm
Plotten Sie die penguins-Daten so dass Sie die Korrelation bill_depth_mm und bill_length_mm innerhalb der Spezies und speziesübergreifend explorieren können.
HinweisHinweis:
Mit add_curve_fit(method = "lm") können Regressionsgeraden eingefügt werden.
TippEine Lösung:
# Speziesübergreifend
penguins %>%
tidyplot(x = bill_depth_mm,
y = bill_length_mm) %>%
add_data_points() %>%
add_curve_fit(method = "lm")
# Für jede Spezies
penguins %>%
tidyplot(x = bill_depth_mm,
y = bill_length_mm,
color = species) %>%
add_data_points() %>%
add_curve_fit(method = "lm")Übung 2: Verteilungsform der flipper_length
Plotten Sie mithilfe des Cheatsheet die Verteilungsform der flipper_length_mm per Spezies in unterschiedlichen Farben als Violinplots und fügen sie das arithmetische Mittel je Species als Punkt hinzu.
TippEine Lösung:
penguins %>%
tidyplot(x = species,
y = flipper_length_mm,
color = species) %>%
add_violin() %>%
add_mean_dot()Cheatsheet {tidyplots}

Literatur
Franconeri, S. L., Padilla, L. M., Shah, P., Zacks, J. M., & Hullman, J. (2021). The Science of Visual Data Communication: What Works. Psychological Science in the Public Interest, 22(3), 110–161.
Grolemund, H. W. and G. (2025). Welcome R for Data Science.
Schneider, J., Schmidt, K., Bohrer, K., & Merk, S. (2025). Communicating Effect Sizes to Teachers: Exploring Different Visualizations and Their Enrichment Options. Zeitschrift für Psychologie, 233(1), 52–63.